Postgres
Cloud Control includes a fully managed Postgres database. This is the default database backend for the following components:
| Component | Userplane | Controlplane |
|---|---|---|
| Dynamic Filtering | yes |
Postgres Cluster
Cloud Control Postgres clusters are deployed with 3 nodes by default, one of which will be designated as primary and the others as replica. The primary node will support both reads & writes, while the replica nodes will only be available for reads. Determination of which node in the cluster is the primary is managed by Patroni. Patroni also makes sure all nodes designated as replica are configured to receive streaming replication from the primary.
Access to the postgres cluster is enabled via 2 services, corresponding to the role of the nodes:
- Primary Service: Exposes the node currently designated as
primary - Replica Service: Exposes the nodes currently designated as
replica
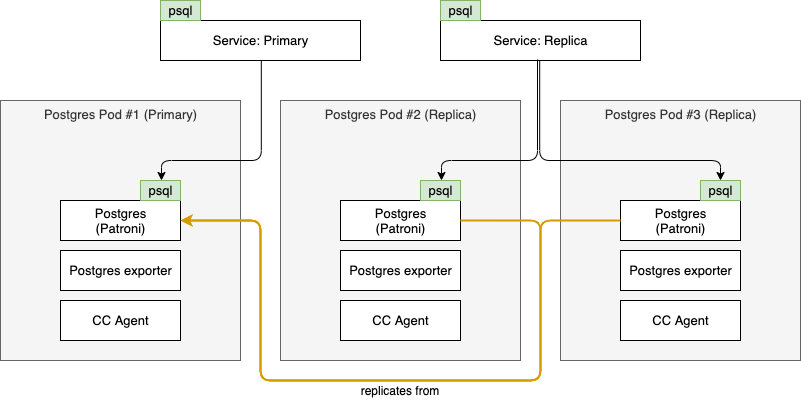
To ensure the Postgres cluster is managed and monitored, each Postgres Pod contains several containers:
- Postgres: Patroni runs in this container, managing the Postgres process and coordinating with Patroni in the other cluster nodes to determine which node is the
primary - Postgres Exporter: Collects Prometheus metrics from Postgres database
- Cloud Control Agent: Responsible for managing the Patroni configuration, exposing metrics and enabling management activities via NATS (such as backup & restore)
This results in a deployment as follows:
Automated failover
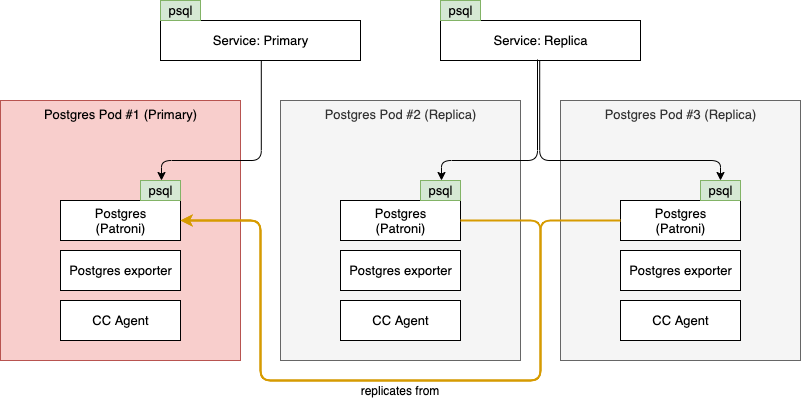
To ensure the Postgres cluster can recover from failures, it always consists of at least 3 nodes. This allows us to ensure that if 1 of the nodes fails or runs on a Kubernetes node undergoing maintenance we can recover and have at least 1 primary and replica left running. The process for failing over is fully managed by Patroni and is best explained using diagrams. In the below scenario, Pod #1 is currently our primary, but it fails:
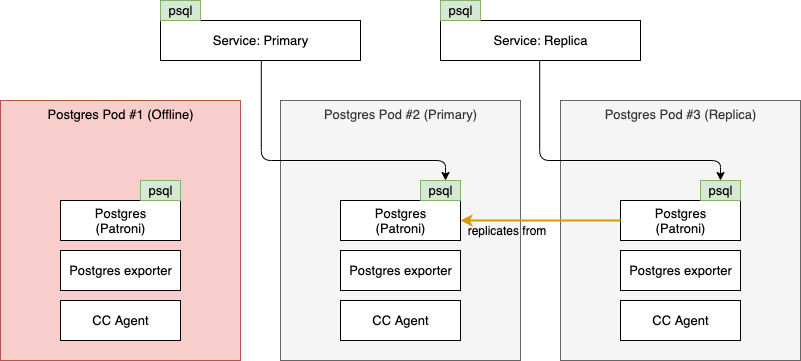
Once Patroni notices the current primary is no longer in a healthy state, a new primary is elected by the remaining nodes and the Service objects and replication are reconfigured accordingly. For example, the cluster will now look as follows:
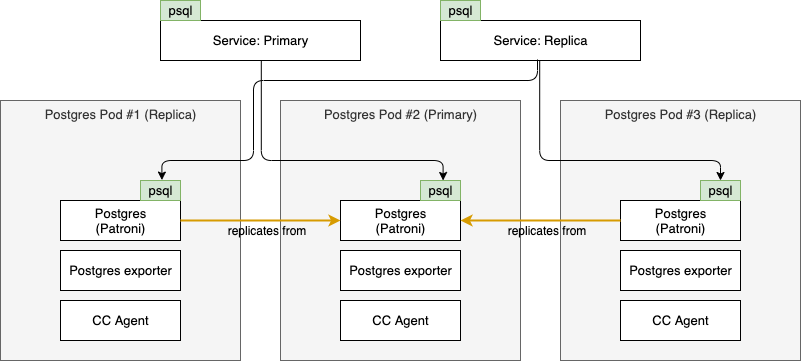
When the cause of the failure of Pod #1 has been determined and resolved, it can rejoin the cluster. It will do so as replica, since another node already took over the role of primary. The cluster will now look like this:
Data Persistency
Persistency of data stored in the postgres cluster is supported by 3 mechanisms:
replicanodes are constantly replicating from theprimaryto ensure aprimaryfailure can be mitigated without data loss- Pods are deployed as part of a StatefulSet with a PersistentVolume on which the Postgres data is stored to ensure the data can withstand a restart of the Pod
- (Optional) Backups to an S3 bucket with support for point-in-time recovery via the Cloud Control API
Backup & Restore
If available, you can configure the Postgres cluster to send full backups and Write-Ahead Logging (WAL) files to an S3 bucket. Using the Cloud Control API you can then perform point-in-time recovery if necessary. The primary tooling between Postgres and the S3 bucket used for these activities is WAL-G.
When backups are enabled, WAL-G will ship full backups and WAL files from the primary node to the S3 bucket:
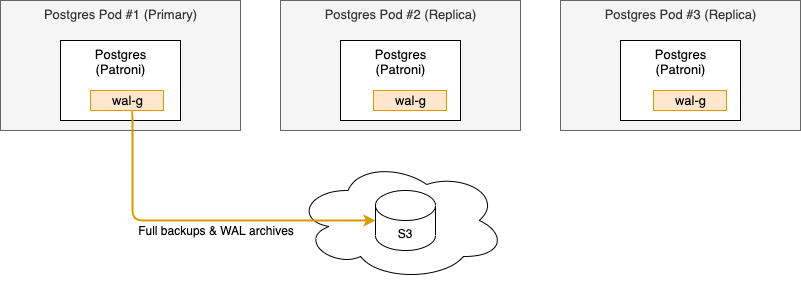
To be able to configure the frequency of full backups it is important to understand how a restore activity works. The process for Cloud Control Postgres follows these steps:
- Administrator issues restore request via Cloud Control API and provides a desired target time to restore to
- Cloud Control determines if there is a full backup available taken prior to the desired target time
- If available, Cloud Control selects the latest full backup that was taken prior to the target time
- If not available, Cloud Control will select the earliest created full backup available
- Cloud Control shuts down Patroni & Postgres on all nodes in the cluster
- Cloud Control removes the current data on the nodes in the cluster
- Cloud Control configures Patroni on a single node (typically the
-0Pod) to restore from the selected full backup and (if available) to the target time using WAL files - Cloud Control starts the newly designated
primarynode to perform the restore - Cloud Control starts the remaining nodes to resynchronize them from the new
primarynode, this happens in sequence as to not overload theprimaryand these all becomereplicanodes
To manage the backups which are available, several mechanisms are available:
- Cloud Control automatically makes a full backup:
- When the cluster is initially created
- After a restore activity has completed
- When an event occurs that causes a
replicanode to become the newprimary - Based on a schedule, configurable in cron format
- Manually, via the Cloud Control API
- Cloud Control Janitor runs on a schedule, also configurable in cron format, which deletes all backups & WAL files older than a configurable number of days
When configuring the backup generation & retention parameters, take the following into account:
- You can only restore to a point-in-time that is as old or more recent than the oldest available full backup
- You can only perform point-in-time recovery from a full backup + WAL files if you have both the full backup and accompanying WAL files available
- WAL files storage usage is primarily determined by:
- Number of days for which they are retained
- Frequency of mutations to the dataset
- Full backups storage usage is primarily determined by:
- Number of days for which they are retained
- Frequency at which they are generated
- Amount of data stored in the database
Info: S3 Object Versioning
S3 providers often have functionality to apply versioning to the items stored in buckets. The Postgres backup functionality does not utilize this functionality.
If you enable object versioning on a bucket used for postgres backups without an appropriate lifecycle policy, you will potentially:
- Use more storage than required (deleted objects linger)
- Run into performance bottlenecks (more objects in bucket = lower performance on some S3 providers)
- Incur higher operating costs (mainly an issue if S3 provider is a public cloud service)
Warning: Do not configure multiple Postgres clusters with the same bucket + prefix
Each Postgres cluster with backups enabled should have a dedicated bucket + prefix combination. If you configure multiple Postgres clusters to use the same bucket + prefix you will likely have conflicting timelines and backups will not be able to be restored properly
Upstream backups
If you have multiple deployments of a Postgres cluster and you wish to be able to restore a backup from one cluster into another, you can configure an upstream S3 storage location from which you wish to be able to restore backups.
Such a configuration would enable the following functionality:
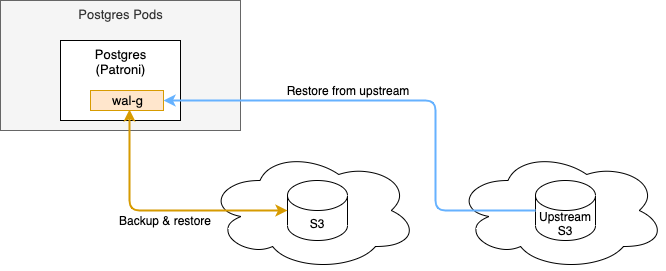
In the above diagram, there are 2 arrows:
- Orange: The cluster's direct backup & restore S3 location, configured via Backup. This is the location where this cluster's backups are written to and from which they can be restored.
- Blue: The additional
upstreamS3 location, configured via Upstream nested under Backup. Since this is anupstreamit can only be used to perform restore activities from, it cannot write backups to this location.
Archived collections
When you perform an upstream restore, the incoming data set will have a timeline which is incompatible with the cluster's current timeline. To accommodate for this timeline from the upstream we need to make sure the cluster's current timeline in the local s3 bucket will not conflict. The logic used to make sure there are no such conflicts is controlled by the archiveCurrentContents flag on the upstream restore functions:
false(default): Cluster's current full backups & WAL files are removed from the local s3 bucket and cannot be recovered.true: Cluster's current full backups & WAL files are copied into a separate location in the local s3 bucket. Such a collection of full backups & corresponding WAL files is referred to as an "archived collection" in the remainder of this documentation.
Interactions with archived collections are as follows:
- List: Generate a list of the archived collections in a cluster's local s3 bucket
- Restore: Restore an archived collection. This will follow these steps:
- Move the current backups & WAL files into a new archived collection
- Copy the desired archived collection into the cluster's active area
- Restore the database to the latest known checkpoint from the desired archived collection
Configuration Reference
Postgres clusters can be configured as nested items of the Cloud Control component which requires it. For example, to configure the Postgres cluster deployed as part of the Dynamic Filtering deployment:
dynamic:
postgres:
backup:
enabled: true
# required:
bucket: mybucket
prefix: pgbackups
endpoint: https://s3.eu-central-1.amazonaws.com
secretName: my-s3-credentials
region: "eu-central-1"
parameters:
max_wal_size: 100
min_wal_size: 40
resources:
limits:
cpu: 4
memory: 4Gi
pvc:
template:
resources:
requests:
storage: 80Gi
Above postgres cluster will have:
- S3 backups enabled
max_wal_sizeandmin_wal_sizePostgres parameters adjusted- Postgres container resource limits set at 4 CPUs and 4 Gi RAM
- Persistent volumes for each Pod with a capacity of 80 Gi
The full list of parameters which can be used under the postgres node in the above YAML are as follows:
| Parameter | Type | Default | Description |
|---|---|---|---|
affinity |
k8s:Affinity |
pod affinity (Kubernetes docs: Affinity and anti-affinity). If unset, a default anti-affinity is applied using antiAffinityPreset to spread pods across nodes |
|
antiAffinityPreset |
string |
"required" |
pod anti affinity preset. Available options: "preferred" "required" |
agentHeartbeat |
integer |
60 |
How often the agent should attempt to synchronize the Postgres database in seconds. This process ensures the database user credentials are kept in sync with the supplied Secrets |
agentLogLevel |
string |
"info" |
Verbosity of logging for the agent container. Available options: "debug" "info" "warn" "error" |
backup |
Backup | |
Configuration of backups, requires an S3 bucket to be available |
hostNetwork |
boolean |
false |
Use host networking for pods |
logLevel |
string |
"info" |
Level of logging. Available options: "debug" "info" "warning" "error" |
nodeSelector |
k8s:NodeSelector |
{} |
Kubernetes pod nodeSelector |
parameters |
dictionary |
{} |
Set of key:value pairs to override Postgres parameters |
podAnnotations |
k8s:Annotations |
{} |
Annotations to be added to each pod |
podLabels |
k8s:Labels |
{} |
Labels to be added to each pod |
podSecurityContext |
k8s:PodSecurityContext |
|
SecurityContext applied to each pod |
primaryService |
Service | |
Configuration of the Service exposing the primary node |
pvc |
Persistent Volume | |
Configuration of the Volume Claim template to request your storage provisioner to provide the Postgres Pods with appropriate persistent storage volumes |
replicas |
integer |
3 |
Default number of replicas in the StatefulSet |
replicaService |
Service | |
Configuration of the Service exposing the replica node(s) |
replicationUser |
User Credentials | {} |
Credentials for the replication user named repluser |
resources |
k8s:Resources |
|
Resources allocated to the postgres container if resourceDefaults (global) is true |
superUser |
User Credentials | {} |
Credentials for the superuser named postgres |
tls |
TLS | |
TLS configuration for inbound Postgres traffic |
tolerations |
List of k8s:Tolerations |
[] |
Kubernetes pod Tolerations |
topologySpreadConstraints |
List of k8s:TopologySpreadConstraint |
[] |
Kubernetes pod topology spread constraints |
Backup
Parameters to configure automated backups if you have an S3 bucket available. For example:
<parent>:
postgres:
backup:
enabled: true
bucket: mybucket
prefix: pgbackups
endpoint: https://s3.eu-central-1.amazonaws.com
secretName: my-s3-credentials
region: "eu-central-1"
Required privileges for backup & restore
The S3 user must have the following privileges on the S3 bucket:
s3:DeleteObjects3:GetObjects3:ListBuckets3:PutObject
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
archiveTimeout |
integer |
300 |
Amount of seconds after which a new WAL file is generated and pushed to the S3 bucket if there has been at least 1 change to the database. On a cluster with low frequency of writes this helps ensure you can always restore to at least archiveTimeout seconds in the past |
|
bucket |
string |
yes |
Name of the S3 bucket | |
enabled |
boolean |
yes |
false |
If true, enable the backup & restore functionality |
endpoint |
string |
yes |
Endpoint of the S3 service to connect to | |
extra |
dictionary |
{} |
Key:value pairs of extra configuration parameters to be added to the WAL-G configuration file used by all backup & restore activities. Only use this if you are aware of potential consequences of the additional configuration items | |
janitorSchedule |
cron |
"0 4 * * *" |
Schedule in cron format to run the Janitor, responsible for deleting backups older than retentionDays days.Defaults to daily at 04:00 (AM) |
|
prefix |
string |
If configured, all backup & restore actions will be performed on the S3 bucket with this prefix applied to all files. | ||
region |
string |
"us-east-1" |
Region of the S3 bucket, some S3 providers require this (AWS for example) and some (such as MinIO) may not require this to be configured | |
retentionDays |
integer |
60 |
Number of days to keep backups in S3. Older backups are deleted by the Janitor | |
schedule |
cron |
"0 2 * * 0" |
Schedule in cron to create full backups. Every time this schedule is activated a full backup will be created.Defaults to every sunday at 02:00 (AM) |
|
secretAccessKey |
string |
"access_key" |
Name of the item inside the secretName Secret which holds the access key |
|
secretName |
string |
yes |
Name of a pre-existing Secret from which to obtain S3 access & secret keys | |
secretSecretKey |
string |
"secret_key" |
Name of the item inside the secretName Secret which holds the secret key |
|
upstream |
Upstream | |
Configuration of S3 storage location of upstream backups, which can be restored into this cluster |
Upstream
Parameters to configure S3 storage location of upstream backups which can be restored into this cluster. Can only be enabled if this Postgres cluster has backups configured. For example:
<parent>:
postgres:
backup:
enabled: true
bucket: mybucket
prefix: pgbackups
endpoint: https://s3.eu-central-1.amazonaws.com
secretName: my-s3-credentials
region: "eu-central-1"
upstream:
enabled: true
bucket: bucketxyz
prefix: upstreambackups
endpoint: https://s3.us-east-1.amazonaws.com
secretName: upstream-s3-credentials
region: "us-east-1"
Required privileges for upstream restores
The upstream S3 user must have the following privileges on the upstream S3 bucket:
s3:GetObjects3:ListBucket
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
bucket |
string |
yes |
Name of the upstream S3 bucket | |
enabled |
boolean |
yes |
false |
If true, enable the upstream restore functionality |
endpoint |
string |
yes |
Endpoint of the S3 service to connect to | |
extra |
dictionary |
{} |
Key:value pairs of extra configuration parameters to be added to the WAL-G configuration file used by all restore activities. Only use this if you are aware of potential consequences of the additional configuration items | |
prefix |
string |
If configured, all restore actions will be performed on the S3 bucket with this prefix applied to all files. | ||
region |
string |
"us-east-1" |
Region of the S3 bucket, some S3 providers require this (AWS for example) and some (such as MinIO) may not require this to be configured | |
secretAccessKey |
string |
"access_key" |
Name of the item inside the secretName Secret which holds the access key |
|
secretName |
string |
yes |
Name of a pre-existing Secret from which to obtain S3 access & secret keys | |
secretSecretKey |
string |
"secret_key" |
Name of the item inside the secretName Secret which holds the secret key |
Persistent Volume
To configure the Persistent Volume requested for each Postgres Pod you can modify the following parameters inside the pvc node:
<parent>:
postgres:
pvc:
labels:
my.prefix/labelname: labelvalue
annotations:
my.prefix/annoname: annovalue
template:
resources:
requests:
storage: 40Gi
These parameters can be configured as follows:
| Parameter | Type | Default | Description |
|---|---|---|---|
annotations |
k8s:Annotations |
{} |
Annotations to be added to the StatefulSet's volume claim template |
template |
k8s:PersistentVolumeClaimSpec |
{} |
Spec of PersistentVolumeClaim. Likely needs to be configured to ensure it complies with the expectations of the storage providers on your Kubernetes cluster. In addition, ensure the requested amount of storage is large enough for your usecase. |
labels |
k8s:Labels |
{} |
Labels to be added to the StatefulSet's volume claim template |
Scaling persistent volume after initial creation
The configuration options listed above are applied only on the initial deployment. Kubernetes does not allow for modification of a persistent volume via the Stateful Set after it has been provisioned.
To modify the persistent volume (for example, to modify the size) after the initial deployment, you will need to scale it using the methodology that is applicable to the storage provisioner used to provision the storage.
Service
Parameters to configure the service objects. For example:
<parent>:
postgres:
primaryService:
type: LoadBalancer
annotations:
metallb.universe.tf/address-pool: name_of_pool
replicaService:
type: LoadBalancer
annotations:
metallb.universe.tf/address-pool: name_of_pool
| Parameter | Type | Default | Description |
|---|---|---|---|
allocateLoadBalancerNodePorts |
boolean |
true |
If true, services with type LoadBalancer automatically assign NodePorts. Can be set to false if the LoadBalancer provider does not rely on NodePorts |
annotations |
k8s:Annotations |
{} |
Annotations for the service |
clusterIP |
string |
Static cluster IP, must be in the cluster's range of cluster IPs and not in use. Randomly assigned when not specified. | |
clusterIPs |
List of string |
List of static cluster IPs, must be in the cluster's range of cluster IPs and not in use. | |
externalIPs |
List of string |
List of IP addresses for which nodes in the cluster will also accept traffic for this service. These IPs are not managed by Kubernetes and must be user-defined on the cluster's nodes | |
externalTrafficPolicy |
string |
Cluster |
Can be set to Local to let nodes distribute traffic received on one of the externally-facing addresses (NodePort and LoadBalancer) solely to endpoints on the node itself |
healthCheckNodePort |
integer |
For services with type LoadBalancer and externalTrafficPolicy Local you can configure this value to choose a static port for the NodePort which external systems (LoadBalancer provider mainly) can use to determine which node holds endpoints for this service |
|
internalTrafficPolicy |
string |
Cluster |
Can be set to Local to let nodes distribute traffic received on the ClusterIP solely to endpoints on the node itself |
ipv4 |
boolean |
false |
If true, force the Service to include support for IPv4, ignoring globally configured IP Family settings and/or cluster defaults. If ipv4 is set to true and ipv6 remains false, the result will be an ipv4-only SingleStack Service. If both are false, global settings and/or cluster defaults are used. If both are true, a PreferDualStack Service is created |
ipv6 |
boolean |
false |
If true, force the Service to include support for IPv6, ignoring globally configured IP Family settings and/or cluster defaults. If ipv6 is set to true and ipv4 remains false, the result will be an ipv6-only SingleStack Service. If both are false, global settings and/or cluster defaults are used. If both are true, a PreferDualStack Service is created |
labels |
k8s:Labels |
{} |
Labels to be added to the service |
loadBalancerIP |
string |
Deprecated Kubernetes feature, available for backwards compatibility: IP address to attempt to claim for use by this LoadBalancer. Replaced by annotations specific to each LoadBalancer provider |
|
loadBalancerSourceRanges |
List of string |
If supported by the LoadBalancer provider, restrict traffic to this LoadBalancer to these ranges | |
loadBalancerClass |
string |
Used to select a non-default type of LoadBalancer class to ensure the appropriate LoadBalancer provisioner attempt to manage this LoadBalancer service | |
publishNotReadyAddresses |
boolean |
false |
Service is populated with endpoints regardless of readiness state |
sessionAffinity |
string |
None |
Can be set to ClientIP to attempt to maintain session affinity. |
sessionAffinityConfig |
k8s:SessionAffinityConfig |
{} |
Configuration of session affinity |
type |
string |
ClusterIP |
Type of service. Available options: "ClusterIP" "LoadBalancer" "NodePort" |
TLS
Parameters to configure TLS for inbound traffic. An example:
In the above example the certificate present in Secret my-cluster-certificate will be attempted to be used to start a TLS-enabled listener.
| Parameter | Type | Default | Description |
|---|---|---|---|
certSecretName |
string |
Name of a Secret object containing a certificate (must contain the tls.key, tls.crt items) |
|
certManager |
boolean |
false |
Toggle to have a request created for Certmanager to provision a certificate. By default, this will request for a Certificate covering the following: - postgres-[Name of cluster]-primary- postgres-[Name of cluster]-primary.[Namespace]- postgres-[Name of cluster]-primary.[Namespace].svc- postgres-[Name of cluster]-replica- postgres-[Name of cluster]-replica.[Namespace]- postgres-[Name of cluster]-replica.[Namespace].svcAdditional entries can be configured using extraDNSNames |
enabled |
boolean |
false |
Toggle to enable TLS If set to true, a certSecretName must be set or certManager must be set to true to ensure a valid certificate is available |
extraDNSNames |
List of string |
[] |
List of additional entries to be added to the Certificate requested from Certmanager |
issuerGroup |
string |
"cert-manager.io" |
Group to which issuer specified under issuerKind belongsDefault value is inherited from the global certManager configuration |
issuerKind |
string |
"ClusterIssuer" |
Type of Certmanager issuer to request a Certificate from Default value is inherited from the global certManager configuration |
issuerName |
string |
"" |
Name of the issuer from which to request a Certificate Default value is inherited from the global certManager configuration |
certSpecExtra |
CertificateSpec | {} |
Extra configuration to be injected into the Certmanager Certificate object's spec field.Disallowed options: "secretName" "commonName" "dnsNames" "issuerRef" (These are configured automatically and/or via other options) |
certLabels |
k8s:Labels |
{} |
Extra labels for the Certmanager Certificate object |
certAnnotations |
k8s:Annotations |
{} |
Extra annotations for the Certmanager Certificate object |
User Credentials
Parameters to configure user credentials. If these are not provided for a user, a password is generated and stored in a Secret named postgres-[Name of cluster]-user-[Username].
For example, to force the superuser (named postgres) to have a password based on the password item in the secret named pg-superuser-password:
| Parameter | Type | Default | Description |
|---|---|---|---|
passwordSecretName |
string |
Name of a Secret object containing a password for the user | |
passwordSecretKey |
string |
password |
Name of the item inside the Secret holding the password |
Administration & Maintenance
Backup & Restore via API
OpenAPI Spec
You can obtain the full OpenAPI spec of the Postgres features offered via the Cloud Control API by deploying it and navigating to the root of the API endpoint.
Warning: Restoration from upstream is incompatible with existing backups
When you perform an upstream restore, you are importing data from a Postgres cluster which has a different history than you currently have available on the target cluster. In Postgres terminology this refers to potentially conflicting timelines.
To ensure the dataset imported from the upstream does not conflict, the default behaviour is to remove all contents from the target cluster's S3 bucket. If you wish to have a copy made of the target cluster's backups prior to importing from the upstream, you can set the archiveCurrentContents parameter to true in the CC API to have a copy created in the S3 bucket's archived/ prefix. These archived backups, also referred to as "archived collections" are retained according to the same retentionDays configuration as regular backups. You can interact with these archived collections using the corresponding API operations.
Note: Since S3 does not have a native "move" or "rename" feature, setting archiveCurrentContents to true will cause each file to be copied to the archived/ folder and then the original will be removed. This can make the upstream restore process take significantly longer, dependent on the amount & size of backups and your S3 provider.
Backup before restore
When you perform any restore activity, you may have data in your existing dataset which has not yet been written to S3 (this could be up to a few minutes worth of data). If you want to ensure you can switch back to the current dataset in the future, you can consider taking a backup using the "Perform full backup" operation before issuing your restore request.
The Cloud Control API currently offers the following operations for Postgres clusters:
| Purpose | Endpoint | Method | Input |
|---|---|---|---|
| List clusters | /postgres/clusters |
GET |
|
| Perform full backup | /postgres/{cluster}/backup |
POST |
cluster: Name of the Postgres cluster |
| List full backups | /postgres/{cluster}/backuplist |
GET |
cluster: Name of the Postgres cluster |
| Perform restore based on timestamp | /postgres/{cluster}/restore |
POST |
cluster: Name of the Postgres clustertimestamp: Date & time to restore toNote: timestamp must be a point in time after which at least 1 transaction was recorded in the available WAL archives |
| Perform restore based on full backup | /postgres/{cluster}/restorebyname |
POST |
cluster: Name of the Postgres clustername: Name of the full backup to restore toapplyIncrementals: If true, apply all available incremental WAL archives created after this full backup up to the moment the next full backup was made (or until the end if no further full backups were taken) |
| List full backups from upstream | /postgres/{cluster}/upstream/backuplist |
GET |
cluster: Name of the Postgres cluster |
| Perform restore based on timestamp from upstream | /postgres/{cluster}/upstream/restore |
POST |
cluster: Name of the Postgres clusterarchiveCurrentContents: If true, make a copy of the current backups prior to wiping the current contents before initiating the upstream restoretimestamp: Date & time to restore toNote: timestamp must be a point in time after which at least 1 transaction was recorded in the available WAL archives |
| Perform restore based on full backup from upstream | /postgres/{cluster}/upstream/restorebyname |
POST |
cluster: Name of the Postgres clustername: Name of the full backup to restore toapplyIncrementals: If true, apply all available incremental WAL archives created after this full backup up to the moment the next full backup was made (or until the end if no further full backups were taken)archiveCurrentContents: If true, make a copy of the current backups prior to wiping the current contents before initiating the upstream restore |
| List archived collections | /postgres/{cluster}/collections/list |
GET |
cluster: Name of the Postgres cluster |
| Restore archived collection | /postgres/{cluster}/collections/restore |
POST |
cluster: Name of the Postgres clustername: Name of the archived collection |
psql
If you need to access the psql CLI inside one of the Postgres pods, you can kubectl exec into a Pod and issue the following command:
Any provided arguments will be passed on to the psql CLI, for example to select the pfadmin database used by dynamic filtering: